⚙️ LLM Engines: Text & Vision
Airparser uses Large Language Model (LLM) engines to extract structured data from documents.
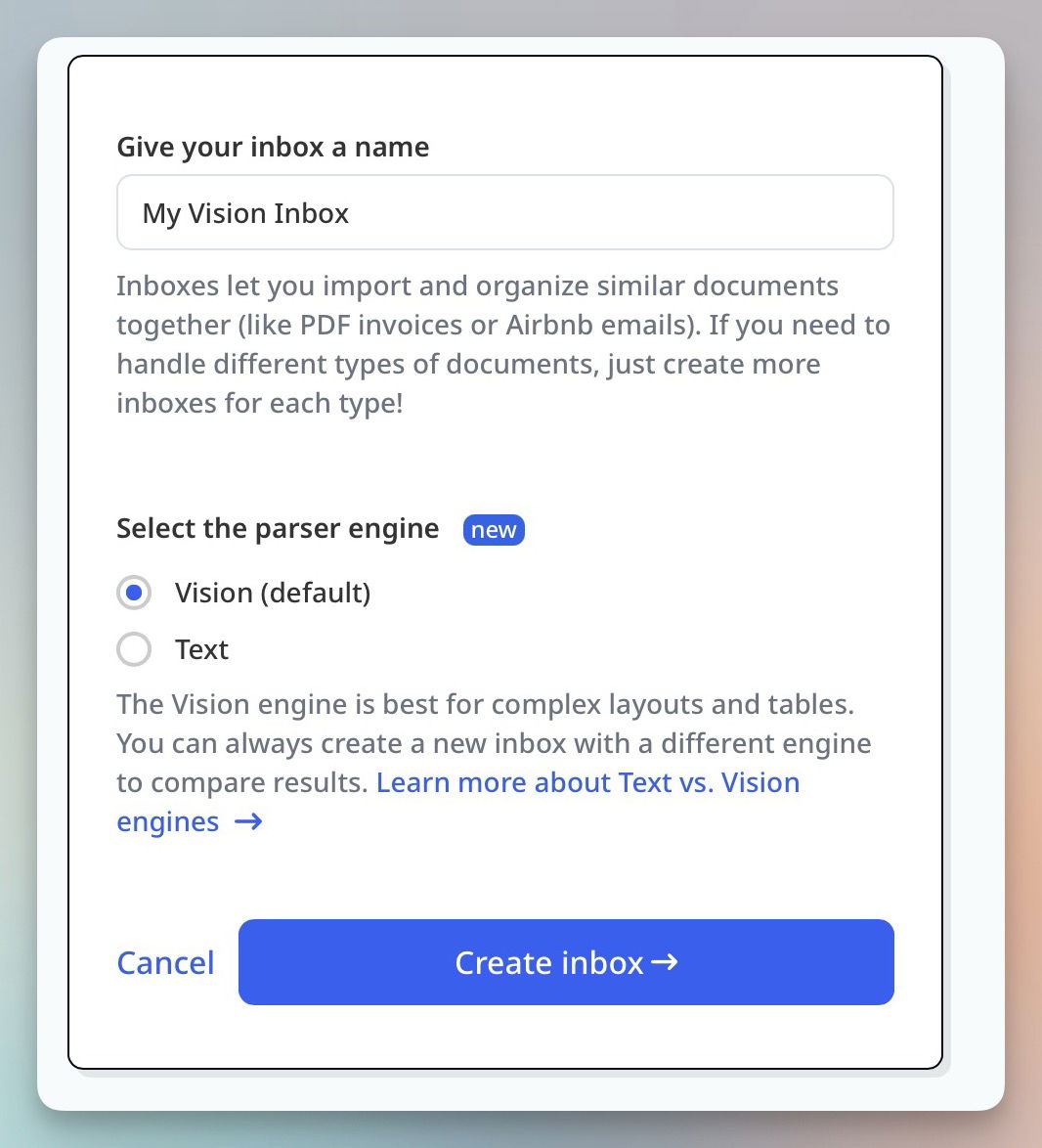
Currently, the Vision engine is the default engine for all new inboxes. You can still switch to the Text engine if it better fits your use case.
Below is an overview of both engines, their differences, and when to use each one.
Vision engine (default)
The Vision engine analyzes documents directly in their original visual form.
It processes the full layout of the document, including text placement, tables, formatting, and images — without relying on OCR as an intermediate step.
Because the model “sees” the document as a whole, it usually provides higher accuracy for complex or visually rich documents.
Key benefits
Preserves layout, tables, and formatting
Works well with scanned documents and images
Better at understanding complex document structures
No information loss caused by OCR text conversion
Text engine
The Text engine is Airparser’s original extraction engine. It works by converting documents into text first and then running the LLM on that text content.
For scanned documents or images, an OCR (Optical Character Recognition) step is required before extraction. While this approach is fast and reliable for many cases, OCR may remove or distort visual details such as table structure, text alignment, fonts, or colors.
When the Text engine works well
Clean, machine-generated documents
Emails and simple PDFs
Documents where layout is not important
Large text-heavy documents
Vision engine limitations
While powerful, the Vision engine has some limitations to be aware of:
Page limit: only the first 10 pages are analyzed
Document alignment: We recommend deskewing (rotating) PDFs and images before importing them
Text clarity: Very small, blurry, or low-quality text may be misinterpreted
Captchas: Captchas are not supported
Human identification: The engine does not identify or recognize people
Medical data: Not suitable for medical imaging or diagnostics (e.g. MRIs, X-rays)
Choosing the right LLM engine
For most users, the Vision engine is the best starting point and is therefore used by default.
You may want to switch to the Text engine if:
Your documents are simple and text-based
Layout and visual structure are not important
You are processing large documents (more than 10 pages)
Speed and cost predictability are a priority
You can always create multiple inboxes with different engines to test which one performs best for your specific documents.

Supported formats
Both engines support the same document formats, including:
Emails
PDFs
Images (JPG, PNG, etc.)
Word documents
Excel
Text files
HTML and more
Pricing
The Vision engine uses the same pricing model as the Text engine.
1 PDF page = 1 credit.